前端工程化其实是软件工程在前端方面的应用,是指将系统化的、规范化的、可度量的方法用于前端应用的开发、运行和维护的过程。其主要的作用有:
- 提升生产效率
- 降低前端开发成本,解放生产力
- 提高前端应用质量(质量保证)
- 降低企业成本
简单说就是研究如何 降本提效和更好地支撑业务。
前端工程化的思维导图参考下图:
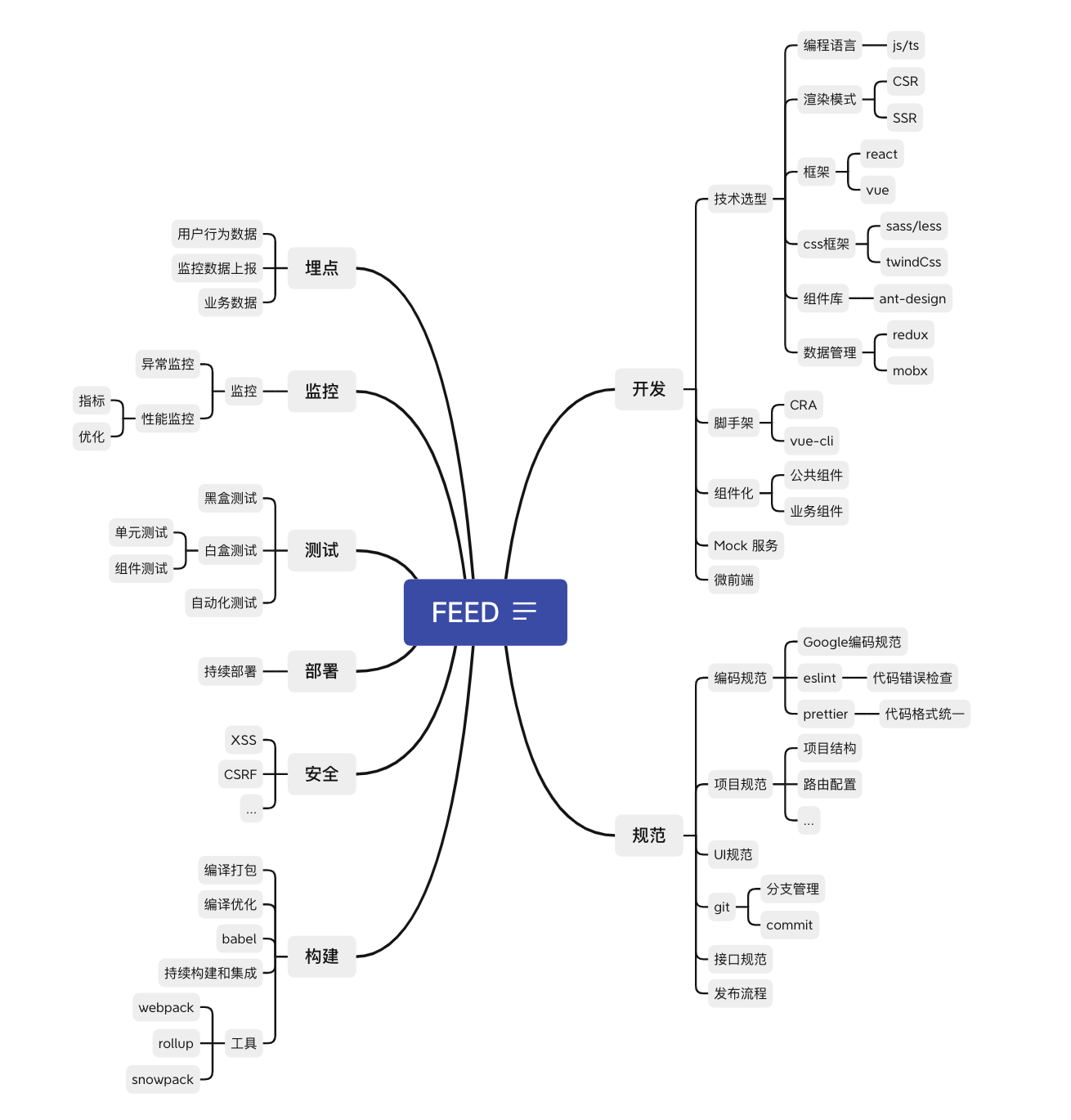
一个简单的研发流程如下:

以上其实只是我个人现阶段对前端工程化的理解,还会持续更新。文章也主要基于以上这个流程来阐述下前端工程化
脚手架
大厂基本上都会自研脚手架,通过 node-cli 去选择和拉取需要的脚手架到本地进行开发,除了统一的项目结构,此时脚手架里面还包含了这次项目所需的依赖和一些基础配置文件,包括 eslint、prettier等代码规范的配置文件
开发
这个阶段是对编码规范、git 规范、项目规范的实践
编码规范
可以参考 Google 的代码风格指南
Git 规范
分支管理规范
- master、release、develop、feature
- 基于 develop 创建新的 feature 分支进行开发
- 如果是多人协作,则需要先额外约定一个合并分支,再基于该分支创建新的 feature 分支
commit 规范
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>- type
feat: 新功能、新特性
fix: 修改 bug
perf: 更改代码,以提高性能
refactor: 代码重构(重构,在不影响代码内部行为、功能下的代码修改)
docs: 文档修改
style: 代码格式修改, 注意不是 css 修改(例如分号修改)
test: 测试用例新增、修改
build: 影响项目构建或依赖项修改
revert: 恢复上一次提交
ci: 持续集成相关文件修改
chore: 其他修改(不在上述类型中的修改)
release: 发布新版本
workflow: 工作流相关文件修改- scope: 这次 commit 影响的范围, 可以是文件夹或者某个文件
- subject: commit 的概述
- body: commit 具体修改内容, 可以分为多行
- footer: 一些备注, 通常是 BREAKING CHANGE 或修复的 bug 的链接
借助 husky 验证 commit 规范,主要通过 git 的 pre-commit 钩子函数来进行
npm i husky -D然后在你项目根目录下新建一个文件夹 script,并在下面新建一个文件 commit-check.js,输入以下代码:
const msgPath = process.env.HUSKY_GIT_PARAMS;
const msg = require("fs").readFileSync(msgPath, "utf-8").trim();
const commitRE =
/^(feat|fix|docs|style|refactor|perf|test|workflow|build|ci|chore|release|workflow)(\(.+\))?: .{1,50}/;
if (!commitRE.test(msg)) {
console.error(`commit 消息不规范`);
process.exit(1);
}最后在 package.json 加上下面的代码
"husky": {
"hooks": {
"pre-commit": "npm run lint",
"commit-msg": "node script/commit-check.js",
"pre-push": "npm test"
}
}- 在
commit之前检查代码格式 - 检查
commit message - 将代码推送到远程仓库前,执行
npm test进行测试,测试失败则不会推送
项目规范
项目结构
文件名称统一使用小写,名称过长用 - 隔开
├─assets (静态资源)
├─components (公共组件)
├─containers (页面)
├─styles (公共样式)
├─routes (路由)
├─store (数据管理)
├─services (接口函数)
├─helper (工具文件夹)
├─request (请求函数)
└─utils (工具函数)其他
- 权限配置
- 路由配置
- 菜单
- …
ui 规范
ui 规范需要由前端、UI/UE、产品商量和制定,建议使用统一的组件库
统一 ui 标准,可以减少前端在开发中由于 ui 设计额外增加的工作量
测试
前端其实很少会做比较规范的测试,毕竟这事吃力不讨好。比较多的应该是用 Jest 做单元测试,主要针对工具函数和公共组件,确保这部分高复用代码的质量
构建
构建这一步主要看使用的构建工具吧,现在主流的还是 webpack,所以针对 webpack 构建会创建好最基础的配置,然后可以做一些编译优化来提升构建速度。以及做持续构建和集成,这一步具体做啥我还不清楚
部署
简单的持续部署可以利用 jenkins 和 webhook 钩子函数来实现,webhook 会监听某个事件,当触发某个事件(比如 push 事件)时,通过钩子函数通知 jenkins 并执行预先设置好的脚本去部署应用
部署时也要讲究一定的策略,减少上线过程造成的异常。可以参考 大公司里怎样开发和部署前端代码?,里面有讲到一些蛮不错的方法
监控
主要分为 性能监控 和 异常监控。作用是监视应用情况、预警和定位问题,然后可以根据应用情况来做一些有效的性能优化。可以通过买 sentry 的服务或者自研的方式实现一个监控系统
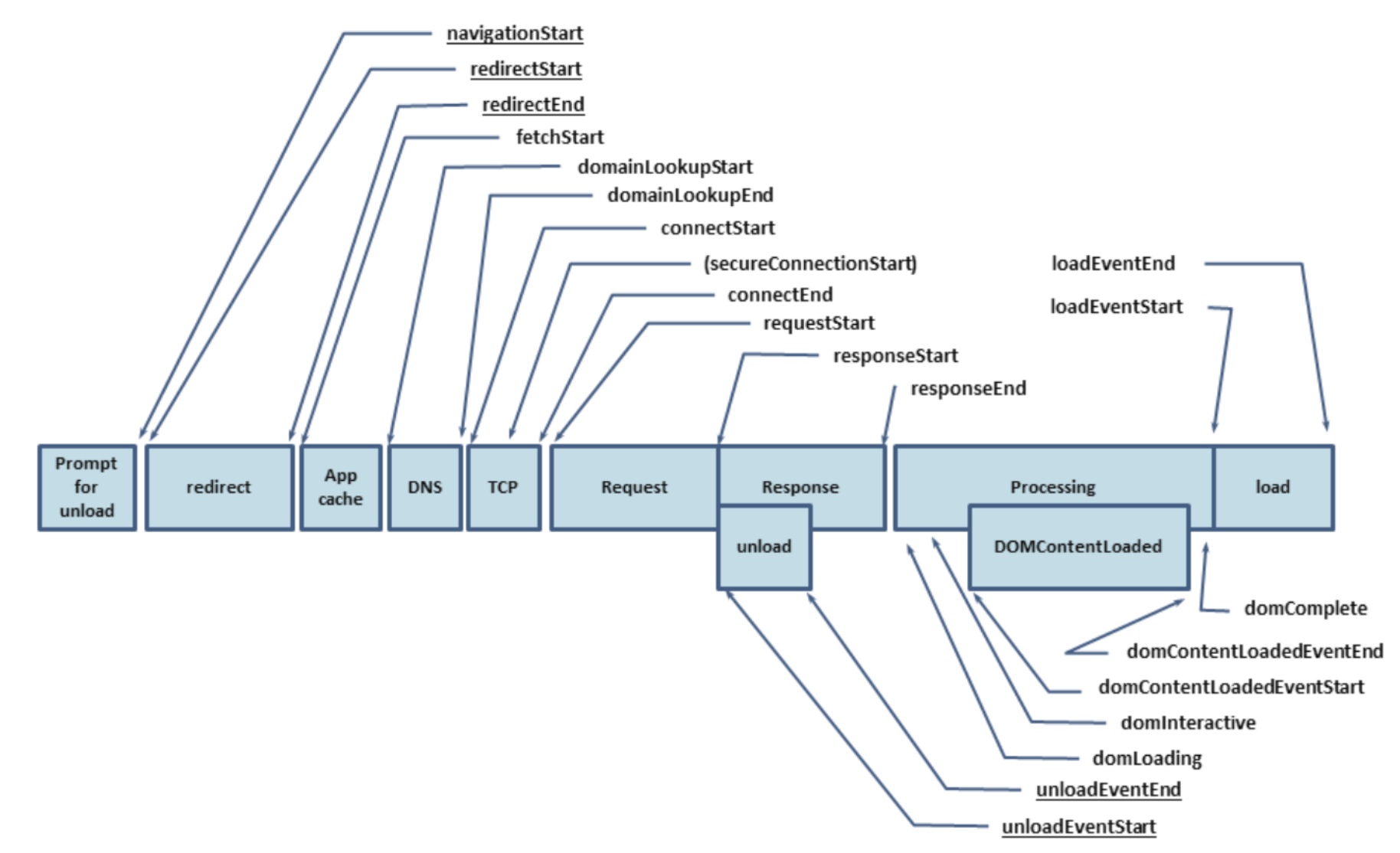
性能监控
一般借助 window.performance 来采集网页的性能指标
异常监控
异常监控其实就是收集应用的报错信息,主要收集以下三种报错信息:
- 资源加载错误
- js 执行报错
- 异步错误,比如 promise。
通过报错收集,可以了解到网站发生错误的类型和数量,从而可以做相应的预防措施来减少网站异常的问题
埋点
- 性能数据上报,由性能监控消费
- 异常数据上报,由异常监控消费
- 用户数据收集和分析(navigator、UV、PV、跳转来源、页面停留时间…)
- 业务数据收集…
最后
以上只是我现阶段对前端工程化的理解和概括,后面我会对工程化的各个环节做更深的探索和实践,进一步夯实前端工程化能力